Prometheusを利用してKubernetesのモニタリング- Prometheus operator チュートリアル(パート3)
Takao Shimizu
Sysdig - Japan Regional Management Technical Officer | Falco.org Website contributor
本文の内容は、2018年9月17日にSysdigのMateo Burilloが投稿したブログ(https://sysdig.com/blog/kubernetes-monitoring-prometheus-operator-part3/)を元に日本語に翻訳・再構成した内容となっております。
このチュートリアルの前章(https://sysdig.com/blog/kubernetes-monitoring-with-prometheus-alertmanager-grafana-pushgateway-part-2/)では、「PrometheusでのKubernetesモニタリング」スタックのインストール方法について説明しました。 しかし、Prometheus Operatorフレームワークとそのカスタムリソース定義を使用すると、メトリクスターゲットとサービスプロバイダを手動で追加するよりも大きな利点があります。一方、大規模展開では煩雑になり、Kubernetesのオーケストレータ機能を十分に活用する事が難しくなります。
今回は、より自動化されフレキシブルな仕方で同じようなスタックをデプロイしていきます。
以前の記事は、下記をカバーしていました:
1 – Kubernetes Monitoring with Prometheus, basic concepts and initial deployment
2 – Kubernetes Monitoring with Prometheus: Alertmanager, Grafana, PushGateway
3 – Prometheus Operator チュートリアル: KubernetesにおけるPrometheus,AlertmanagerとGrafanaの完全自動化デプロイ (今回):
- Kubernetes Operatorとは?
- Prometheus Operatorについて
- Prometheus Operator - クイックインストール
- オートコンフィグ メトリクスエンドポイント
- アラートルールとAlertmanagerコンポーネント
- Grafanaでビジュアライゼーションとダッシュボード
4 – Prometheus performance considerations, high availability, external storage, dimensionality limits.
Kubernetes Operatorとは?
オペレーターは、Kubernetesに特化したアプリケーション(pod)であり、Kubernetes deploymentの設定、管理、そして最適化を行います。それらは、カスタムコントローラーとして実装されています。Kubernetesオペレーターは、アプリケーションのデプロイとスケーリングのノウハウをカプセル化しています。そして、API経由でアルゴリズムも実行します。
Kubernetes Operatorは、下記の例ようなユーザに優しい事をしてくれます:
- 利用しているKubernetesクラスタの仕様に従って、インストール、適切な初期設定とDeploymentのサイジングを提供
- ユーザがリクエストしたパラメーター変更に対してDeploymentとpodのライブリロードの実行(hot config reloading)
- パフォーマンスメトリクスに基づいて自動でスケールアップ・ダウン
- Perform backups, integrity checks or any other maintenance task.
- バックアップや機能性チェック、その他メンテナンスタスクの実行
基本的に、人間の管理者がコードとして表現できるものは、Kubernetes Operatorとして自動化する事が可能です。
Kubernetes Operatorは、コンテキスト固有のエンティティやオブジェクトを作成するために、他のKubernetes APIリソースと同様にアクセスする、カスタムリソース定義(Custom Resource Definitions:CRD)を広範に使用します。 たとえば、次のセクションでは、Prometheusサーバーデプロイメントの初期設定と規模を定義している「Prometheus」Kubernetes APIオブジェクトとかかわっていきます。 オペレータはCRDの読み取り、書き込み、更新を行い、クラスタ内のサービス設定を保持します。
Prometheus Operatorについて
Kubernetes用のPrometheus Operatorは、Kubernetesサービスを簡単にモニタリングできる定義やPrometheusインスタンスのデプロイメントと管理を提供しています。
今回は、Prometheus Operatorを下記のように使用していきます:
- Kubernetes-Prometheusスタックの初期インストールと設定を行います。
- Prometheus servers
- Alertmanager
- Grafana
- Host node_exporter
- kube-state-metrics
- ServiceMonitorエンティティを使用してエンドポイント自動設定メトリクスを定義
- Operator CRDとConfigMapを用いてサービスをカスタマイズ、スケールさせるように、コンフィグレーションを完全にポータブルで宣言的にします。
Operatorは以下のカスタムリソース定義(CRD) を遂行します:
- Prometheus、要求されたPrometheusデプロイメントを定義します。Operatorは常に、リソース定義と一致するデプロイメントが実行されていることを確認します。
- ServiceMonitor、サービスのグループをモニターする方法を宣言的に指定します。Operatorは、Prometheusのscrape設定を定義に基づいて自動的に生成します。
- PrometheusRuleは、必要なPrometheusルールファイルを定義します。これは、Prometheusアラートおよび記録ルールを含むPrometheusインスタンスによってロードできます。
- Alertmanagerは、要求されたAlertmanagerデプロイメントを定義します。 Operatorは常に、リソース定義と一致するデプロイメントが実行されていることを確認します。
Operatorリポジトリ内のkube-prometheusディレクトリにはデフォルトのサービスと設定が含まれているので、Prometheus Operator自体だけでなく、get-goからカスタマイズやカスタマイズを始めることができる完全なセットアップを利用できます。
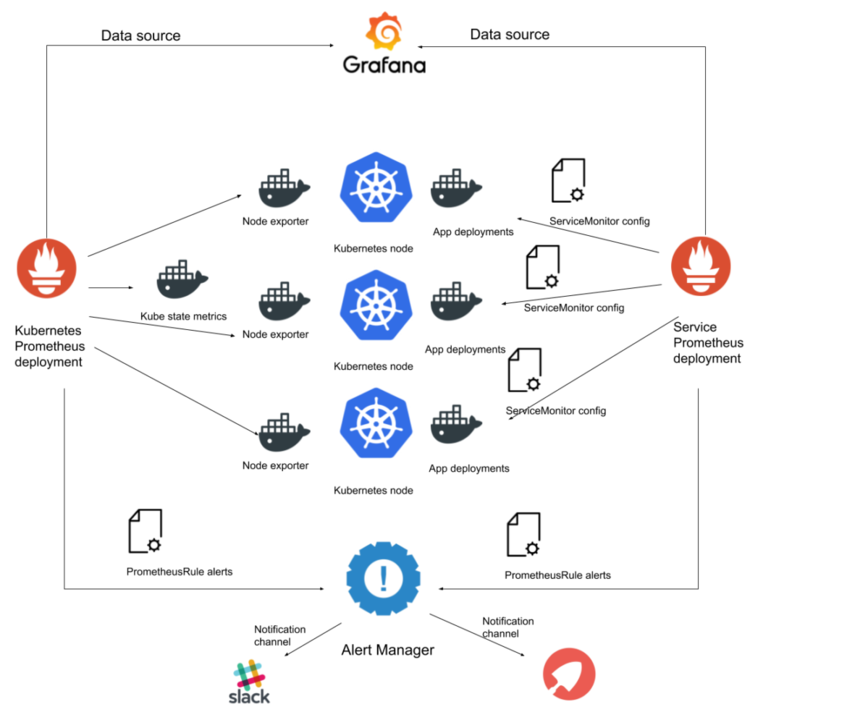
Prometheus Operator – コンポーネントアーキテクチャー図
以下は、こらから構築するKubernetes モニタリングシステムのコンポーネント図です:

この図は、パート2のものと似ている事に気づかれましたでしょうか?以前は、Prometheusコンポーネントを手動でインストールを行いましたが、この2つのデプロイメントには重要な違いがあります:
- 異なるPrometheus デプロイメントで異なるリソースをモニタリング:
- 1つのPrometheusサーバグループ(規模に応じて1からNまで)がKubernetesの内部コンポーネントと状態をモニタリングします。
- 別グループのPrometheusサーバがクラスター内にデプロイされている他のアプリをモニタリングします。
- DeploymentとServiceを直接作成する代わりに、CRDを使用してOperatorにメトリクスソースを提供します。 上の例では、2つのデータソースを持つ1つのGrafanaサービスがありますが、Prometheus Operatorを使って宣言的にコンポーネント図を並べ替える方法を示します。
Prometheus Operator – クイックインストール
prometheus-monitoring-guideリポジトリには、使用する基本のyamlファイルとカスタマイズの例がいくつか含まれています。 まず最初にリポジトリのクローンを作成します。
git clone https://github.com/coreos/prometheus-operator.git
git clone https://github.com/mateobur/prometheus-monitoring-guide.git
ローカルのkubectlが稼働中のkubernetesクラスタを指していることを確認してください。簡単に破棄して再作成できるテストベット用のクラスタを使用する事ができれば、様々な構成を試す事もできます。
kube-prometheusをデフォルトの設定を使ってインストールするには下記を実行するだけです:
kubectl create -f prometheus-operator/contrib/kube-prometheus/manifests/
デフォルトのスタックは、多くのコンポーネントを”out of the box”でデプロイします:
kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 7m
alertmanager-main-1 2/2 Running 0 7m
alertmanager-main-2 2/2 Running 0 6m
grafana-5568b65944-nwbct 1/1 Running 0 8m
kube-state-metrics-76bdcb8ff9-77t52 4/4 Running 0 6m
node-exporter-224sh 2/2 Running 0 7m
node-exporter-2s89j 2/2 Running 0 7m
node-exporter-x8w8b 2/2 Running 0 7m
prometheus-k8s-0 3/3 Running 1 7m
prometheus-k8s-1 3/3 Running 1 6m
prometheus-operator-cdccdb8db-vcvhx 1/1 Running 0 8m
以下を確認できます:
- prometheus-operator pod、PrometheusサーバやAlertmanagerサーバのような他のデプロイメントの管理を行うスタックのコアです。
- 物理ホスト毎のnode-exporter pod(この例では3つです)
- kube-state-metrics exporter
- デフォルトのPrometheusサーバデプロイメント prometheus-k8s(replicas:2)
- デフォルトのAlertmanagetデプロイメント alertmanager-main(replicas:3)
- Grafanaデプロイメント grafana (replicas: 1)
Prometheus Operatorインターフェースを使用する
デプロイしたインターフェースをクイックに確認するために、kubectl port-forward機能を活用してみましょう。
kubectl port-forward grafana-5568b65944-nwbct -n monitoring 3000:3000
Webブラウザーで http://localhost:3000 にアクセスすると、Grafanaインターフェースにアクセスできます。Grafanaでは、いくつかの便利なダッシュボードを確認することもできるでしょう。

しかし、本番用のKubernetesのモニタリングを導入する場合には、ingress controllerを利用して適切なセキュリティの元に公開する必要があります:HTTPS certificateと認証が必要です。
CRDオブジェクトを介してPrometheus Operatorを利用する
Kubernetesで想定されている各コンポーネントのDeploymentもしくは、StatefulSetを変更するのではなく、このPrometheus stack deploymentを変更するには、抽象定義を直接カスタマイズしてOperatorにオーケストレーションを処理させて行きます。
では、シンプルな例をやってみましょう:このシナリオは、3つの Alertmanager podが多すぎるという事で始めて見ます。 まず始めに alertmanager CRDを見ていきましょう:
kubectl get alertmanager main -n monitoring -o yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
clusterName: ""
creationTimestamp: 2018-08-28T09:15:25Z
labels:
alertmanager: main
name: main
namespace: monitoring
resourceVersion: "1401"
selfLink: /apis/monitoring.coreos.com/v1/namespaces/monitoring/alertmanagers/main
uid: e5d335aa-aaa2-11e8-8cf2-42010a800113
spec:
baseImage: quay.io/prometheus/alertmanager
nodeSelector:
beta.kubernetes.io/os: linux
replicas: 3
serviceAccountName: alertmanager-main
version: v0.15.2
version: v0.15.2
ここから、pod labels、serviceAccount、nodeSelector、replicasの数を変更できます。
replicasパラメータを「1」に変更し、APIオブジェクトにパッチを適用します(パッチを適用したバージョンはprometheus-monitoring-guideリポジトリにあります)。
kubectl create -f prometheus-monitoring-guide/operator/alertmanager.yaml --dry-run -o yaml | kubectl apply -f -
monitoring namespaceのpodリストを見ると、Prometheus OperatorのログにAlertmanager podとresizeイベントが1つだけ表示されます。
kubectl logs prometheus-operator-cdccdb8db-vcvhx -n monitoring | tail -n 1
level=info ts=2018-08-28T09:47:20.523662127Z caller=operator.go:402 component=alertmanageroperator msg="sync alertmanager" key=monitoring/main
autoconfigrationをPrometheus Operator endpointに施す
次のステップでは、この設定を基にして、クラスタにデプロイされている他のサービスのモニタリングを行って見ましょう
このプロセスには、2つのカスタムリソースがあります:
- Prometheus CRD
- Prometheus server pod metadataの定義
- Prometheus server replicas 数の定義
- トリガーされたアラートルールを送信するためのAlertmanager(s) endpointの定義
- Prometheusサーバーによって適用されるServiceMonitor CRDのラベルとnamespaceフィルターの定義
- ServiceMonitorオブジェクトは、dynamic target endpoint configurationを提供します。
- TServiceMonitor CRD
- namespace, labels等でendpointをフィルターします
- 異なる “scraping port”を定義 -> “scraping port”≒情報取得用のポートの意味を示していると思われます。
- 情報取得間隔、使用するプロトコル、TLS認証情報、再ラベル付けポリシーなど、追加の”scraping parameter”を定義
Prometheusオブジェクトは、N個のServiceMonitorオブジェクトをフィルタリングして選択し、N個のServiceMonitorオブジェクトがN個のPrometheusメトリックエンドポイントをフィルタリングして選択します。
ServiceMonitor基準に一致する新しいメトリックスエンドポイントがある場合、このターゲットはそのServiceMonitorを選択するすべてのPrometheusサーバーに自動的に追加されます。

上の図でわかるように、ServiceMonitorはポッドによって直接公開されているエンドポイントではなく、Kubernetesサービスをターゲットにしています。
すでに、すべてのKubernetes内部メトリックをモニタリングするPrometheusをデプロイ(kube-state-metrics, node-exporter, Kubernetes API等)しています。しかし、クラスタの上で実行されている他のアプリケーションを処理するためには、個別のdeployment が必要です。
この新しいDeploymentを行うには、まずクラスタに適用する前にこのPrometheus CRDを見てみましょう(このファイルは以下のリポジトリにあります)。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app: prometheus
prometheus: service-prometheus
name: service-prometheus
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
baseImage: quay.io/prometheus/prometheus
logLevel: info
paused: false
replicas: 2
retention: 2d
routePrefix: /
ruleSelector:
matchLabels:
prometheus: service-prometheus
role: alert-rules
serviceAccountName: prometheus-k8s
serviceMonitorSelector:
matchExpressions:
- key: serviceapp
operator: Exists
簡潔にするために、もう一方のDeploymentにあるalertmanagerおよびserviceAccountの設定を再利用します。
このPrometheusサーバー設定ファイルには、次のものがあります。
- この設定を使用しているPrometheus replicas数(2)
- アラートルールを動的に設定するruleSelector
- トリガーされたアラートを受け取るAlertmanager deployment(冗長性のために複数のポッドになる可能性があります)
- ServiceMonitorSelector、これは、このPrometheusサーバーの設定に特定のserviceMonitorを使用するかどうかを決定するフィルタです。
- この例では、serviceMonitorにメタデータにラベルserviceappが含まれている場合、serviceMonitorをこのPrometheusデプロイメントに関連付けることにしました。
必要に応じて、リポジトリから直接新しい設定を適用することができます:
kubectl create -f prometheus-monitoring-guide/operator/service-prometheus.yaml
ここでは、Prometheus Operatorが新しいAPIオブジェクトに気付き、あなたにぴったりのデプロイメントを作成します:
prometheus-service-prometheus-0 3/3 Running 1 12m
prometheus-service-prometheus-1 3/3 Running 1 12m
これらのポッドのいずれかのインターフェイスに接続して見て見ると、メトリクスターゲットはまだありません。別途、情報を取得する(scrape)サービスが必要です。もし、すでに何かしらをインストールされていれば問題ありませんが、もし、インストールしていない場合は、Helmを使用してクイックに実行させることもできます。
CoreDNSは、Cloud Native Computing Foundationのインキュベーションレベルのプロジェクトです。高速で柔軟性のあるDNSサーバーです。 あなたのクラスタにhelmがセットアップされている場合は、以下を実行してください。
kubectl create ns coredns
helm install --name coredns --namespace=coredns stable/coredns
CoreDNSは、追加設定の必要無しで、Prometheusメトリクスを公開しています(port 9153を使用):
kubectl get svc -n coredns
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
coredns-coredns ClusterIP 10.11.253.94 <none> 53/UDP,53/TCP,9153/TCP 3m
これで、ServiceMonitorを使用して、この新しいサービスを自分のServices Prometheus deploymentに接続できます(以下に示すように、このファイルはリポジトリにあります)。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
serviceapp: coredns-servicemonitor
name: coredns-servicemonitor
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 15s
port: metrics
namespaceSelector:
matchNames:
- coredns
selector:
matchLabels:
release: coredns
クラスターに適用します:
kubectl create -f prometheus-monitoring-guide/operator/servicemonitor-coredns.yaml
数秒後、Prometheusインターフェース内の"scraping"ターゲットを見ると、設定が自動的に更新され、このターゲットからメトリックを受け取っていることがわかります:

さらに、このCoreDNS deploymentのサービング pod(つまりメトリクスエンドポイント)の数を増やすと、次のようになります。
helm upgrade coredns stable/coredns --set replicaCount=3
すべてのターゲットはServiceMonitorによって自動的に検出され、Prometheusの設定に登録されます:

Prometheus Operator – Alert Rules設定方法
ServiceMonitorと非常によく似た概念であるPrometheusRule CRDを使用して、Prometheus deploymentでKubernetesモニタリングアラートを設定できます。
Prometheus deploymentを定義していたとき、これらのオブジェクトをフィルタリングして一致させるための設定ブロックがありました:
ruleSelector: matchLabels: prometheus: service-prometheus
role: alert-rules
PromQLルールを含むオブジェクトを定義した場合、それらはPrometheusサーバーの設定に自動的に追加されます(このファイルは以下のようにリポジトリにあります)。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: service-prometheus
role: alert-rules
name: prometheus-service-rules
namespace: monitoring
spec:
groups:
- name: general.rules
rules:
- alert: TargetDown-serviceprom
annotations:
description: '{{ $value }}% of {{ $labels.job }} targets are down.'
summary: Targets are down
expr: 100 * (count(up == 0) BY (job) / count(up) BY (job)) > 10
for: 10m
labels:
severity: warning
- alert: DeadMansSwitch-serviceprom
annotations:
description: This is a DeadMansSwitch meant to ensure that the entire Alerting
pipeline is functional.
summary: Alerting DeadMansSwitch
expr: vector(1)
labels:
severity: none
リポジトリから適用します:
kubectl create -f prometheus-monitoring-guide/operator/prometheusrules.yaml
すぐにservice-prometheusインターフェースからこれらの警告を調べることも可能です。 external ingressを設定したくない場合は、ローカルポートフォワードを使用します:
kubectl port-forward prometheus-service-prometheus-0 -n monitoring 9090:9090
Prometheusサーバーインターフェースの[Alerts]タブにアクセスします。

DeadManSwitchは常に起動するアラートの一般的な名前であり(常にtrueと評価される起動条件があります)、アラートパイプラインが期待どおりに機能していることを確認するためにあります。 この状態がロードされて数秒後に、上の画像のように、明るい赤の背景の上にアラート名が表示されるはずです。
Alertmanagerインターフェース(ポート9093)を開くと、このPrometheusデプロイメントからのアラートを見ることができます。 external ingressを設定したくない場合は、ローカルポートフォワードを使用します。
kubectl port-forward alertmanager-main-0 -n monitoring 9093:9093

Prometheus Operator – Grafanaダッシュボードの定義
現時点では、Prometheus OperatorのGrafanaコンポーネント用のカスタムリソース定義はありません。Grafanaの設定を管理するために、Kubernetes secretとConfigMap(新しいデータソースや新しいダッシュボードを含む)を使用します。
Prometheus Operatorを使用してデプロイされたGrafanaを使用する場合、データソースはGrafanaがKubernetes secret から読み取るbase64を使用してエンコードされたデータ構造として定義されます。
secret dataを復号すると、これに似たものが見えるはずです:
kubectl get secret grafana-datasources -n monitoring -o jsonpath --template '{.data.prometheus.yaml}' | base64 -d
{
"apiVersion": 1,
"datasources": [{
"access": "proxy",
"editable": false,
"name": "prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://prometheus-k8s.monitoring.svc:9090",
"version": 1
}]
}
}
同じJSONフォーマットを使って新しいデータソースを追加し、secret dataをbase64で再エンコードしてsecretを更新するだけです。
新しいファイルを作成してみましょう:
{
"apiVersion": 1,
"datasources": [
{
"access": "proxy",
"editable": false,
"name": "prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://prometheus-k8s.monitoring.svc:9090",
"version": 1
},
{
"access": "proxy",
"editable": false,
"name": "service-prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://service-prometheus.monitoring.svc:9090",
"version": 1
}
]
}
secret objectにEncapsulateします(自身のファイルを使うことも、下に示すようにリポジトリからそれを使うこともできます):
kubectl create secret generic grafana-datasources -n monitoring --from-file=./prometheus-monitoring-guide/operator/grafana/prometheus.yaml --dry-run -o yaml > grafana-datasources.yaml
そして、API内のGrafana secretにパッチを当てます:
kubectl patch secret grafana-datasources -n monitoring --patch "$(cat grafana-datasources.yaml)"
データソースはPrometheus podではなくサービスを指すことに注意してください。このファイルを使用してservice-prometheus.monitoring.svcサービスを作成する必要があります。
kubectl create -f prometheus-monitoring-guide/operator/prometheus-svc.yaml
最後のGrafanaを再起動します:
kubectl delete pod grafana-5568b65944-szhx4 -n monitoring
そして、UIの[datasources]タブに移動し(必要ならばポートフォワードをもう一度使用します。ポート3000)、両方のPrometheus deployment がデータソースとして表示されます:

Prometheus Operatorを使用して、Kubernetes ConfigMap内のDashboard JSONデータをエンコードするだけで、Grafanaダッシュボードを外部から読み込むことができます:
kubectl get cm -n monitoring
NAME DATA AGE
grafana-dashboard-k8s-cluster-rsrc-use 1 20d
grafana-dashboard-k8s-node-rsrc-use 1 20d
grafana-dashboard-k8s-resources-cluster 1 20d
grafana-dashboard-k8s-resources-namespace 1 20d
grafana-dashboard-k8s-resources-pod 1 20d
これらのConfigMapは、Grafana deployment定義に明示的にマウントされています。
kubectl get deployments grafana -n monitoring -o yaml
...
- mountPath: /grafana-dashboard-definitions/0/pods
name: grafana-dashboard-pods
...
- configMap:
defaultMode: 420
name: grafana-dashboard-pods
name: grafana-dashboard-pods
ダッシュボードごとに新しいConfigMapを作成して、Grafana podを管理するデプロイメント定義に対応するエントリを追加できます。
このガイドの第2部で説明したように、もう1つの、おそらくより柔軟なオプションは、Dashboard設定のアップグレードを自動的に処理するGrafana Helmチャートを使用することです。
結論
Prometheus Operatorを使用して、宣言的で再現可能な方法で、Kubernetesモニタリングスタックをより少ない労力で構築することができました。これは、スケール変更、変更、または別のホストセットへの移行も容易になります。
これまで、Prometheusテクノロジースタックを使用してKubernetesクラスタをモニタリングする機能、利点、および魅力的な可能性について説明してきました。 ただし、大規模なデプロイメントを実行する前に、その欠点や注意点についても知っておく必要もあります。次に例を示します。
- メトリクスの長期保存:前述したように、Prometheusは長期メトリックスの保存(およびバックアップ、データの冗長性、傾向分析、データマイニングなどの密接に関連する問題)を抽象化しています。 このガイドの第2部では、完全なストレージソリューションにおける基本的な構成要素を提供する最小限デプロイメントについて説明しています。
- Authorization と Authentication:プロジェクトのドキュメントで指摘されているように、Prometheusとそのコンポーネントはサーバー側の認証、承認、または暗号化を提供しません。 異なるレベルのアクセス権を持つユーザーのグループ、または他のRBACフレームワークはありません。
- バーティカルおよびホリゾンタルなスケーラビリティ:それほど大きな欠点ではなく、むしろ目標とする容量について十分な情報に基づいた決定を下すために事前に計画する必要があります。このガイドの最後の部分で、Prometheusのパフォーマンスに関する考慮事項、高可用性、および連携について説明します。
PrometheusとSysdig(商用のモニタリングプラットフォーム)の比較については、Prometheus MonitoringとSysdig Monitor:技術比較をご覧ください。